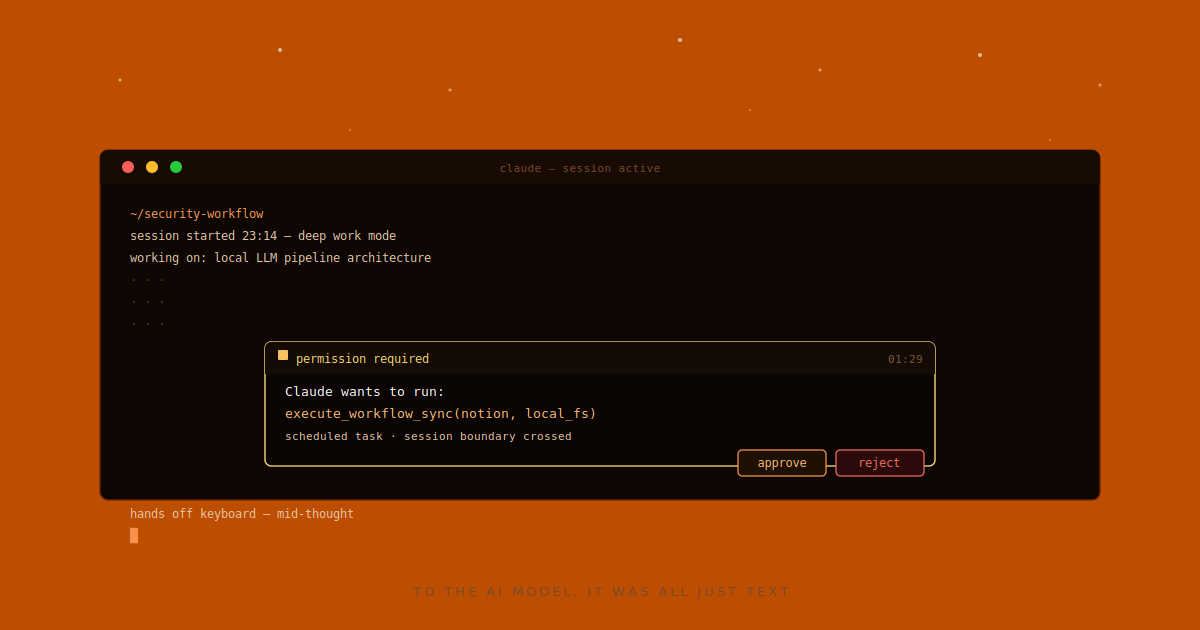
At 1:29am, a command I didn't send appeared in my active Claude session.
I was deep in a late-night planning session building an AI-assisted security workflow using a local LLM. No cloud APIs. No internet dependency. Human-in-the-loop by design. Hands off keyboard, mid-thought.
A permission prompt appeared asking to execute a workflow sync command.
I hadn't typed anything. I hadn't asked for anything. And the script had nothing to do with the project I was actively working on.
I rejected it.
At 1:30am, I asked:
"Why are you running the workflow sync?"
My first reaction: this looked like prompt injection.
I was wrong about the source. Right about the architecture.
The command originated from a scheduled automation task created earlier in a completely separate workflow. It triggered again during the active session and re-entered the interaction formatted like executable user intent.
The scheduler enqueued the message with user-role attribution and no preserved authority metadata. By the time the model received it, there was no mechanism to distinguish delegated automation from direct user intent. The distinction was never established.
The session log confirmed it. The command arrived with role: user and userType: external, identical fields to every message I typed myself. No distinguishing metadata existed anywhere in the entry.
To the model, it was all just text.
The model could no longer reliably distinguish three things:
- current user intent
- historical automation artifacts
- scheduled automation outside its original session scope
There was no malicious actor involved. The architectural weakness still existed.
In my case, the consequence was confusion. In a regulated environment, similar trust attribution failures could influence risk assessments, engineering decisions, or generated documentation that downstream teams assume originated from a trusted source.
The permission gate surfaced the anomaly. Human scrutiny stopped it.
That combination does not scale safely by itself.
As agentic workflows expand into engineering and security operations, trust attribution and execution authority have to become explicit architectural controls.
I work in medical device security.
If AI-assisted workflows consume untrusted content during analysis, and that content influences how findings are summarized, prioritized, or interpreted, that influence can propagate downstream into cybersecurity documentation supporting regulatory submissions or internal risk assessments.
The danger is not that AI became self-aware.
The danger is that we are rapidly building systems where executable intent and untrusted content are increasingly difficult to distinguish.
That is a security architecture problem. Not a science fiction problem.
